filmov
tv
How to Implement Pagination in Your Web Scraper for Dynamic Content

Показать описание
Learn how to effectively use pagination in your web scraper to handle dynamic content, ensuring you capture all the data you need.
---
Disclaimer/Disclosure: Some of the content was synthetically produced using various Generative AI (artificial intelligence) tools; so, there may be inaccuracies or misleading information present in the video. Please consider this before relying on the content to make any decisions or take any actions etc. If you still have any concerns, please feel free to write them in a comment. Thank you.
---
How to Implement Pagination in Your Web Scraper for Dynamic Content
When building a web scraper, one of the key challenges you might face is handling dynamic content and pagination. Proper implementation of pagination ensures that you can capture all the data available across multiple pages.
Understanding Pagination
Pagination is the process of dividing a large set of data across multiple pages to enhance the user experience and improve loading times. For web scrapers, this means navigating through each page to collect comprehensive data.
Why Is Pagination Important?
Without proper pagination, your scraper might only collect data from the first page, missing out on additional valuable information available on subsequent pages. This is particularly important for sites with dynamic content that loads page content dynamically.
Implementing Pagination in Your Web Scraper
Here are the steps to implement pagination in your web scraper:
Identify the Pagination Logic
Each website uses a different logic for pagination, such as "next" buttons, infinite scroll, or numbered pages. Inspect the HTML of web pages to understand how pagination is structured. Look for HTML elements like <a>, <button>, or JavaScript events tied to navigation.
URL Pattern Examination
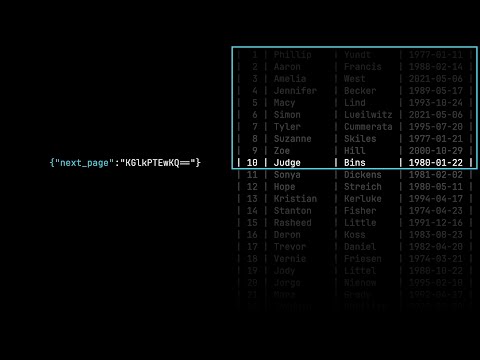
Many websites use predictable URL patterns for pagination, such as:
[[See Video to Reveal this Text or Code Snippet]]
Recognizing these patterns allows you to increment the page number in your script and request data from subsequent pages.
Automate Page Navigation
Use libraries tailored for web scraping, such as BeautifulSoup and Requests in Python, to automate the navigation across page links.
[[See Video to Reveal this Text or Code Snippet]]
Handling Dynamic Content with Tools like Apify
In cases where content loads dynamically, traditional scraping methods may fail. Apify is a powerful tool that integrates with web scraping and automation platforms to handle dynamic content effectively. Apify allows you to build actors and custom solutions, leveraging its in-built support for pagination.
Implement Error Handling and Throttling
Web scraping can put a load on servers. Implementing error handling and throttling techniques prevents your scraper from being blocked and ensures smoother data extraction. Utilize HTTP error codes, retry mechanisms, and specify delay intervals between requests.
[[See Video to Reveal this Text or Code Snippet]]
Final Thoughts
Implementing pagination is key to successful data extraction in web scraping, especially when dealing with dynamic content. By understanding how pagination works and utilizing tools like Apify, you can ensure your scraper captures all the necessary data efficiently.
---
Disclaimer/Disclosure: Some of the content was synthetically produced using various Generative AI (artificial intelligence) tools; so, there may be inaccuracies or misleading information present in the video. Please consider this before relying on the content to make any decisions or take any actions etc. If you still have any concerns, please feel free to write them in a comment. Thank you.
---
How to Implement Pagination in Your Web Scraper for Dynamic Content
When building a web scraper, one of the key challenges you might face is handling dynamic content and pagination. Proper implementation of pagination ensures that you can capture all the data available across multiple pages.
Understanding Pagination
Pagination is the process of dividing a large set of data across multiple pages to enhance the user experience and improve loading times. For web scrapers, this means navigating through each page to collect comprehensive data.
Why Is Pagination Important?
Without proper pagination, your scraper might only collect data from the first page, missing out on additional valuable information available on subsequent pages. This is particularly important for sites with dynamic content that loads page content dynamically.
Implementing Pagination in Your Web Scraper
Here are the steps to implement pagination in your web scraper:
Identify the Pagination Logic
Each website uses a different logic for pagination, such as "next" buttons, infinite scroll, or numbered pages. Inspect the HTML of web pages to understand how pagination is structured. Look for HTML elements like <a>, <button>, or JavaScript events tied to navigation.
URL Pattern Examination
Many websites use predictable URL patterns for pagination, such as:
[[See Video to Reveal this Text or Code Snippet]]
Recognizing these patterns allows you to increment the page number in your script and request data from subsequent pages.
Automate Page Navigation
Use libraries tailored for web scraping, such as BeautifulSoup and Requests in Python, to automate the navigation across page links.
[[See Video to Reveal this Text or Code Snippet]]
Handling Dynamic Content with Tools like Apify
In cases where content loads dynamically, traditional scraping methods may fail. Apify is a powerful tool that integrates with web scraping and automation platforms to handle dynamic content effectively. Apify allows you to build actors and custom solutions, leveraging its in-built support for pagination.
Implement Error Handling and Throttling
Web scraping can put a load on servers. Implementing error handling and throttling techniques prevents your scraper from being blocked and ensures smoother data extraction. Utilize HTTP error codes, retry mechanisms, and specify delay intervals between requests.
[[See Video to Reveal this Text or Code Snippet]]
Final Thoughts
Implementing pagination is key to successful data extraction in web scraping, especially when dealing with dynamic content. By understanding how pagination works and utilizing tools like Apify, you can ensure your scraper captures all the necessary data efficiently.
 0:03:12
0:03:12
 0:07:40
0:07:40
 0:03:06
0:03:06
 0:13:57
0:13:57
 0:13:10
0:13:10
 0:14:47
0:14:47
 0:13:20
0:13:20
 0:00:43
0:00:43
 0:05:05
0:05:05
 0:13:06
0:13:06
 0:23:21
0:23:21
 0:01:21
0:01:21
 0:00:16
0:00:16
 0:15:02
0:15:02
 0:01:07
0:01:07
 0:24:02
0:24:02
 0:08:50
0:08:50
 0:09:15
0:09:15
 0:22:45
0:22:45
 0:01:25
0:01:25
 0:00:39
0:00:39
 0:11:39
0:11:39
 0:11:29
0:11:29
 0:10:11
0:10:11