filmov
tv
AWS Tutorials - Using AWS Glue ETL Job with Streaming Data

Показать описание
Recently AWS announced streaming data support for AWS Glue ETL Jobs which helps in setting up continuous ingestion pipelines that processes streaming data on the fly. Streaming ETL jobs consume data from streaming sources likes Amazon Kinesis and Apache Kafka, clean and transform those data streams in-flight, and continuously load the results into Amazon S3 data lakes, data warehouses, or other data stores.
In this workshop, you create an ETL job which will read streaming data from Kinesis data stream and upload to Amazon S3 bucket. The ETL job will transform data from JSON to CSV format. The data to Kinesis stream is published using MQTT client using AWS IoT Core.
 0:09:12
0:09:12
AWS In 10 Minutes | AWS Tutorial For Beginners | AWS Cloud Computing For Beginners | Simplilearn
 0:05:30
0:05:30
AWS In 5 Minutes | What Is AWS? | AWS Tutorial For Beginners | AWS Training | Simplilearn
 9:28:40
9:28:40
AWS Tutorial For Beginners | AWS Full Course - Learn AWS In 10 Hours | AWS Training | Edureka
 0:11:46
0:11:46
Top 50+ AWS Services Explained in 10 Minutes
 0:38:54
0:38:54
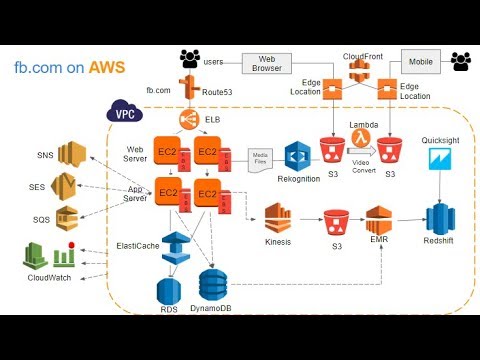
Introduction to AWS Services
 0:50:07
0:50:07
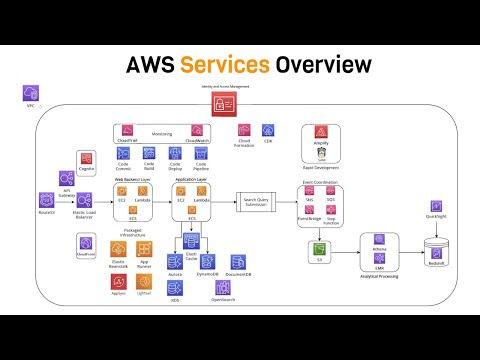
Intro to AWS - The Most Important Services To Learn
 0:23:54
0:23:54
Getting Started With AWS Cloud | Step-by-Step Guide
 0:49:26
0:49:26
AWS & Cloud Computing for beginners | 50 Services in 50 Minutes
 0:12:30
0:12:30
Amazon Q Apps Tutorial | Generative AI Powered Apps with AWS
 0:25:34
0:25:34
AWS SageMaker Tutorial | Introduction To AWS SageMaker | AWS Tutorial For Beginners | Simplilearn
 0:22:17
0:22:17
AWS EC2 Tutorial For Beginners | What Is AWS EC2? | AWS EC2 Tutorial | AWS Training | Simplilearn
 0:25:10
0:25:10
Containers on AWS Overview: ECS | EKS | Fargate | ECR
 2:03:24
2:03:24
AWS Tutorial on Amazon EC2
 0:26:52
0:26:52
Getting Started with AWS | Amazon Web Services BASICS
 0:12:34
0:12:34
Amazon/AWS EC2 (Elastic Compute Cloud) Basics | Create an EC2 Instance Tutorial |AWS for Beginners
 0:07:29
0:07:29
What is Amazon Web Services? AWS Explained | Tutorial & Resources
 0:12:44
0:12:44
Create Your First AWS Lambda Function | AWS Tutorial for Beginners
 2:11:42
2:11:42
AWS VPC Beginner to Pro - Virtual Private Cloud Tutorial
 0:27:18
0:27:18
AWS S3 Tutorial For Beginners
 2:00:23
2:00:23
AWS Tutorial For Beginners | AWS Certified Solutions Architect | AWS Training | Edureka
 0:00:43
0:00:43
Deploying a Website to AWS in Under 1 Minute
 13:26:00
13:26:00
AWS Certified Cloud Practitioner Certification Course (CLF-C01) - Pass the Exam!
 0:26:13
0:26:13
AWS Project: Architect and Build an End-to-End AWS Web Application from Scratch, Step by Step
 0:07:38
0:07:38
you need to learn AWS RIGHT NOW!! (Amazon Web Services)
Комментарии