filmov
tv
GPT-4 Tutorial: How to Chat With Multiple PDF Files (~1000 pages of Tesla's 10-K Annual Reports)
Показать описание
In this video we'll learn how to use OpenAI's new GPT-4 api to 'chat' with and analyze multiple PDF files. In this case, I use three 10-k annual reports for Tesla (~1000 PDF pages)
OpenAI recently announced GPT-4 (it's most powerful AI) that can process up to 25,000 words – about eight times as many as GPT-3 – process images and handle much more nuanced instructions than GPT-3.5.
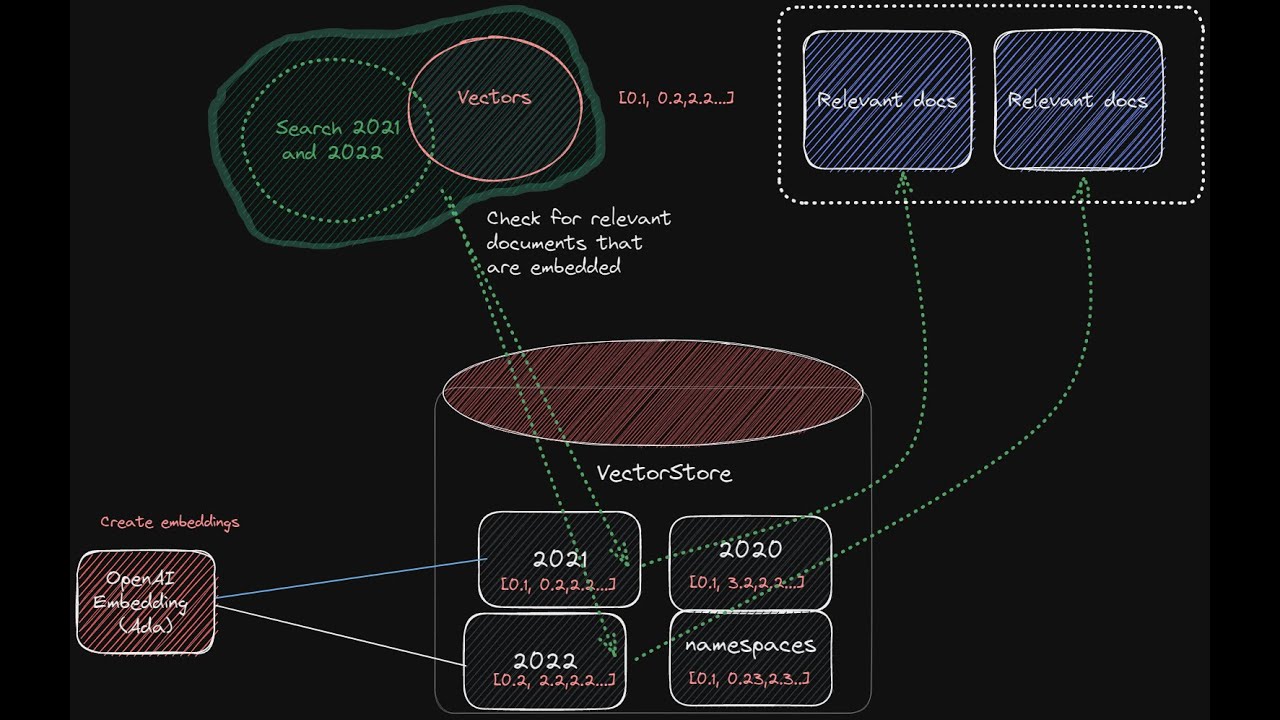
You'll learn how to use LangChain (a framework that makes it easier to assemble the components to build a chatbot) and Pinecone - a 'vectorstore' to store your documents in number 'vectors'. You'll also learn how to create a frontend chat interface to display the results alongside source documents.
A similar process can be applied to other usecases you want to build a chatbot for: PDF's, websites, excel, or other file formats.
Visuals & Code:
🖼 Visual guide download + github repo (this is the base template used for this demo):
Timestamps:
01:02 PDF demo (analysis of 1000-pages of annual reports)
06:01 Visual overview of the multiple pdf chatbot architecture
17:40 Code walkthrough pt.1
25:15 Pinecone dashboard
28:30 Code walkthrough pt.2
#gpt4 #investing #finance #stockmarket #stocks #trading #openai #langchain #chatgpt #langchainjavascript #langchaintypescript #langchaintutorial
OpenAI recently announced GPT-4 (it's most powerful AI) that can process up to 25,000 words – about eight times as many as GPT-3 – process images and handle much more nuanced instructions than GPT-3.5.
You'll learn how to use LangChain (a framework that makes it easier to assemble the components to build a chatbot) and Pinecone - a 'vectorstore' to store your documents in number 'vectors'. You'll also learn how to create a frontend chat interface to display the results alongside source documents.
A similar process can be applied to other usecases you want to build a chatbot for: PDF's, websites, excel, or other file formats.
Visuals & Code:
🖼 Visual guide download + github repo (this is the base template used for this demo):
Timestamps:
01:02 PDF demo (analysis of 1000-pages of annual reports)
06:01 Visual overview of the multiple pdf chatbot architecture
17:40 Code walkthrough pt.1
25:15 Pinecone dashboard
28:30 Code walkthrough pt.2
#gpt4 #investing #finance #stockmarket #stocks #trading #openai #langchain #chatgpt #langchainjavascript #langchaintypescript #langchaintutorial
 0:11:00
0:11:00
ChatGPT 4 Tutorial: How to Use Chat GPT 4 For Beginners 2024
 0:20:22
0:20:22
ChatGPT 4 Tutorial - How to Use Chat GPT 4 For Beginners
 0:13:54
0:13:54
How To Use GPT-4o (GPT4o Tutorial) Complete Guide With Tips and Tricks
 0:27:51
0:27:51
ChatGPT Tutorial: How to Use Chat GPT For Beginners 2024
 0:21:42
0:21:42
ChatGPT Plus: Tutorial su Come Funziona con GPT 4! Immagini, PDF, Dati..
 0:04:28
0:04:28
ChatGPT's Voice Conversations Tutorial
 0:21:32
0:21:32
Beginners Guide to GPT4 API & ChatGPT 3.5 Turbo API Tutorial
 0:09:08
0:09:08
ChatGPT sul PC SENZA LIMITI: Tutorial AI LOCALE + API GPT-4
 0:01:57
0:01:57
💀 ChatGPT 4 mod apk 2024 | chatgpt 4 image generator free | ChatGPT 4 free access with AI art
 0:11:42
0:11:42
ChatGPT Tutorial für Anfänger in 2024 🤖 ALLE wichtigen Grundlagen
 0:56:00
0:56:00
ChatGPT Tutorial 2024: How to Use ChatGPT - Beginner to Pro!
 0:34:05
0:34:05
ChatGPT Tutorial - A Crash Course on Chat GPT for Beginners
 0:20:26
0:20:26
How to Create Custom GPT | OpenAI Tutorial
 0:12:12
0:12:12
ChatGPT Tutorial - How to use Chat GPT for Learning and Practicing English
 0:29:14
0:29:14
ChatGPT Functions - Full Tutorial for using OpenAI Functions
 0:29:47
0:29:47
Sofistik and GPT-4 Tutorial: How to talk to your structural model
 0:28:13
0:28:13
ChatGPT Tutorial for Developers - 38 Ways to 10x Your Productivity
 0:07:50
0:07:50
Advanced ChatGPT Prompt Tutorial (10X Your Productivity With AI)
 0:00:41
0:00:41
ChatGPT For Multiple PDF files (5000 Page PDF's) GPT-4 Tutorial.
 0:08:08
0:08:08
How to Use ChatGPT Plus (Complete Tutorial)
 0:11:59
0:11:59
ChatGPT 4o Canvas Full Tutorial! *NEW 2024*
 0:10:09
0:10:09
How to use free Chat GPT 4-O Malayalam Tutorial
 0:09:19
0:09:19
How to use ChatGPT 4o for FREE! | ChatGPT Tutorial | ChatGPT 4o tips and tricks
 0:27:32
0:27:32
Complete ChatGPT Tutorial - [Become A Power User in 30 Minutes]
Комментарии