filmov
tv
AWS Tutorials - Introduction to AWS Glue Studio

Показать описание
The Glue Studio Workshop -
PySpark Transformation Workshops –
AWS Glue Studio is GUI based service to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It helps in visually composing data transformation workflows and run them on AWS Glue’s Apache Spark-based serverless ETL engine. AWS Glue Studio supports both tabular and semi-structured data. AWS Glue Studio also offers tools to monitor ETL workflows and validate that they are operating as intended.
In this workshop, you create an ETL job using AWS Glue Studio which reads data from the data lake data catalog, performs transformation and writes to the S3 bucket.
PySpark Transformation Workshops –
AWS Glue Studio is GUI based service to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. It helps in visually composing data transformation workflows and run them on AWS Glue’s Apache Spark-based serverless ETL engine. AWS Glue Studio supports both tabular and semi-structured data. AWS Glue Studio also offers tools to monitor ETL workflows and validate that they are operating as intended.
In this workshop, you create an ETL job using AWS Glue Studio which reads data from the data lake data catalog, performs transformation and writes to the S3 bucket.
 0:09:12
0:09:12
AWS In 10 Minutes | AWS Tutorial For Beginners | AWS Cloud Computing For Beginners | Simplilearn
 0:38:54
0:38:54
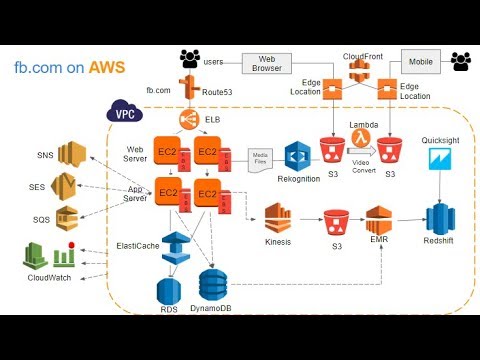
Introduction to AWS Services
 0:50:07
0:50:07
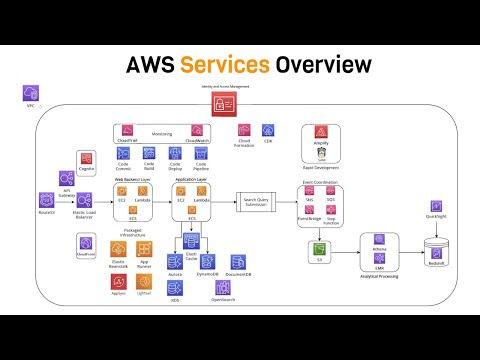
Intro to AWS - The Most Important Services To Learn
 0:05:30
0:05:30
AWS In 5 Minutes | What Is AWS? | AWS Tutorial For Beginners | AWS Training | Simplilearn
 0:49:26
0:49:26
AWS & Cloud Computing for beginners | 50 Services in 50 Minutes
 9:28:40
9:28:40
AWS Tutorial For Beginners | AWS Full Course - Learn AWS In 10 Hours | AWS Training | Edureka
 0:25:34
0:25:34
AWS SageMaker Tutorial | Introduction To AWS SageMaker | AWS Tutorial For Beginners | Simplilearn
 0:23:54
0:23:54
Getting Started With AWS Cloud | Step-by-Step Guide
 0:12:30
0:12:30
Amazon Q Apps Tutorial | Generative AI Powered Apps with AWS
 0:11:46
0:11:46
Top 50+ AWS Services Explained in 10 Minutes
 0:09:05
0:09:05
What is AWS? | AWS Tutorial For Beginners | Introduction to Amazon Web Services | Simplilearn
 0:07:29
0:07:29
What is Amazon Web Services? AWS Explained | Tutorial & Resources
 3:58:01
3:58:01
AWS Certified Cloud Practitioner Training 2020 - Full Course
 0:30:02
0:30:02
Introduction to AWS Networking
 0:56:02
0:56:02
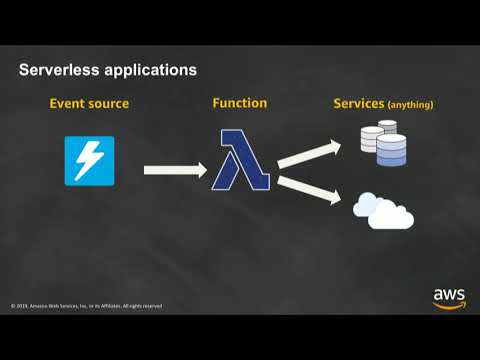
Introduction to AWS Lambda & Serverless Applications
 0:03:47
0:03:47
An Introduction to AWS CDK (and why you should be using it!)
 0:41:43
0:41:43
AWS Services Overview | Introduction To AWS Services | AWS Tutorial For Beginners | Simplilearn
 0:07:17
0:07:17
How I would learn AWS Cloud (If I could start over)
 0:25:10
0:25:10
Containers on AWS Overview: ECS | EKS | Fargate | ECR
 0:26:52
0:26:52
Getting Started with AWS | Amazon Web Services BASICS
 0:22:17
0:22:17
AWS EC2 Tutorial For Beginners | What Is AWS EC2? | AWS EC2 Tutorial | AWS Training | Simplilearn
 13:26:00
13:26:00
AWS Certified Cloud Practitioner Certification Course (CLF-C01) - Pass the Exam!
 2:00:23
2:00:23
AWS Tutorial For Beginners | AWS Certified Solutions Architect | AWS Training | Edureka
 9:22:38
9:22:38
AWS Complete Tutorial 2023 | Learn Amazon Web Services from Scratch | Cloud Computing | @SCALER
Комментарии