filmov
tv
ChatGPT For Your DATA | Chat with Multiple Documents Using LangChain

Показать описание
ChatGPT For Your DATA | Chat with Multiple Documents Using LangChain
In this video, I will show you, how you can chat with any document. Let's say you have a folder and inside the folder, you have different file formats. Let's say you have PDF file. You have text file. You have read me file and others. I will show you how you can take all of your data, split the data into different chunks, do the embeddings using the OpenAI embeddings, store that into the Pinecone vectorstore. Finally, you can just chat with your own documents and get insights out of it, similar to ChatGPT for with your own data. Happy Learning.
👉🏼 Links:
🔗 Other videos you might find helpful:
💰🔗 Some links are affiliate links, meaning, when you use those, I might get some benefit.
#openai #llm #datasciencebasics #chatwithdata #documents #chatgpt #nlp
In this video, I will show you, how you can chat with any document. Let's say you have a folder and inside the folder, you have different file formats. Let's say you have PDF file. You have text file. You have read me file and others. I will show you how you can take all of your data, split the data into different chunks, do the embeddings using the OpenAI embeddings, store that into the Pinecone vectorstore. Finally, you can just chat with your own documents and get insights out of it, similar to ChatGPT for with your own data. Happy Learning.
👉🏼 Links:
🔗 Other videos you might find helpful:
💰🔗 Some links are affiliate links, meaning, when you use those, I might get some benefit.
#openai #llm #datasciencebasics #chatwithdata #documents #chatgpt #nlp
 0:17:42
0:17:42
Train ChatGPT On Your Data (Easy Method)
 0:16:29
0:16:29
Using ChatGPT with YOUR OWN Data. This is magical. (LangChain OpenAI API)
 0:00:55
0:00:55
Chat GPT: How To Train ChatGPT On Your Own Data (Quick 2024)
 0:03:55
0:03:55
3 Ways ChatGPT Can Leak YOUR Data
 0:15:18
0:15:18
Create your own ChatGPT with CUSTOM PDF Data using LangChain | Gen AI Use Case | Satyajit Pattnaik
 0:03:07
0:03:07
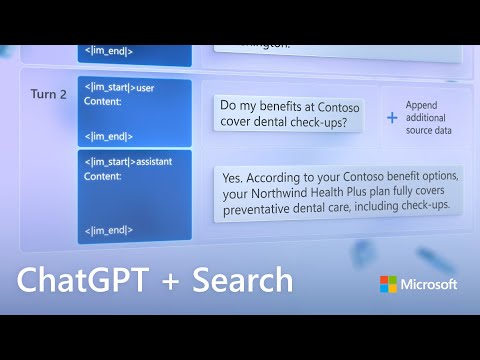
How to Train ChatGPT with Your Own Data
 0:15:56
0:15:56
Can ChatGPT work with your enterprise data?
 0:09:15
0:09:15
Create Your Own ChatGPT with PDF Data in 5 Minutes (LangChain Tutorial)
 0:14:27
0:14:27
Web scraping in R with ChatGPT (4 Examples) no HTML knowledge needed
 0:08:25
0:08:25
How to Use ChatGPT with Your Own Data
 0:09:31
0:09:31
ChatGPT for your data with 5 lines of code
 0:09:07
0:09:07
Azure OpenAI BYOD: ChatGPT with Your Own Data!
 0:11:41
0:11:41
How To Train ChatGPT AI WIth Your Data
 0:10:09
0:10:09
Safely Use ChatGPT with Your Data
 0:01:23
0:01:23
Does ChatGPT save your data? (And how to turn it off.)
 0:21:31
0:21:31
Chat with Your SQL Data Using ChatGPT
 0:00:55
0:00:55
Apply ChatGPT to your own data.
 0:06:48
0:06:48
How to Use ChatGPT-4 Advanced Data Analysis - Analyse your data with AI
 0:01:01
0:01:01
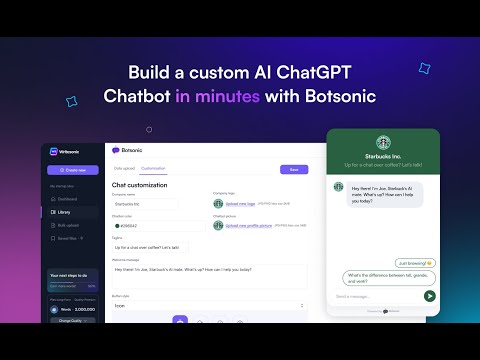
How to train ChatGPT on your data? Discover with Botsonic #chatgpt #chatgptalternative
 0:03:22
0:03:22
Does ChatGPT store your data and can you stop it?
 0:02:02
0:02:02
How To Train ChatGPT On Your Own Data Tutorial
 0:18:05
0:18:05
Get your data into ChatGPT: CSV, JSON, Databases & more
 0:53:51
0:53:51
Train AI on Your Data... In 3 Levels
 1:11:45
1:11:45
Train ChatGPT on your data
Комментарии