filmov
tv
K Nearest Neighbor | KNN | sklearn KNeighborsClassifier

Показать описание
In this presentation, we have shown the KNN classification of the Iris dataset to classify the targeted output for a new instance.
K Nearest Neighbour is a simple way to classify data. K defines the number of nearest neighbors (individual data points). If we put a new instance in the data set to find the category the new instance matches with, we calculate its nearest neighbors. The most amount of neighbor the data point is close to, the instance falls into that category.
Here we have shown here:
[00:00:00] - Intro
[00:02:28] - KNN Algorithm
[00:03:00] - Sci-Kit Learn KNeighborsClassifier
[00:03:36] - Implementation of KNN
[00:06:03] - Confusion Matrix
[00:07:04] - Classification Report
[00:08:01] - How to find the best value for K
[00:09:00] - K-Fold Cross-Validation Technique
#DataScience #MachineLearning #ComputerScience #AI
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
K Nearest Neighbour is a simple way to classify data. K defines the number of nearest neighbors (individual data points). If we put a new instance in the data set to find the category the new instance matches with, we calculate its nearest neighbors. The most amount of neighbor the data point is close to, the instance falls into that category.
Here we have shown here:
[00:00:00] - Intro
[00:02:28] - KNN Algorithm
[00:03:00] - Sci-Kit Learn KNeighborsClassifier
[00:03:36] - Implementation of KNN
[00:06:03] - Confusion Matrix
[00:07:04] - Classification Report
[00:08:01] - How to find the best value for K
[00:09:00] - K-Fold Cross-Validation Technique
#DataScience #MachineLearning #ComputerScience #AI
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 0:02:13
0:02:13
K Nearest Neighbors | Intuitive explained | Machine Learning Basics
 0:08:01
0:08:01
What is the K-Nearest Neighbor (KNN) Algorithm?
 0:05:30
0:05:30
StatQuest: K-nearest neighbors, Clearly Explained
 0:01:34
0:01:34
Simple Explanation of the K-Nearest Neighbors (KNN) Algorithm
 0:27:43
0:27:43
KNN Algorithm In Machine Learning | KNN Algorithm Using Python | K Nearest Neighbor | Simplilearn
 0:08:30
0:08:30
Machine Learning | K-Nearest Neighbor (KNN)
 0:04:42
0:04:42
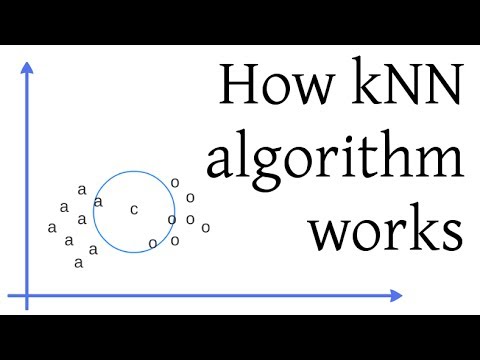
How kNN algorithm works
 0:15:42
0:15:42
Machine Learning Tutorial Python - 18: K nearest neighbors classification with python code
 0:00:59
0:00:59
Simplifying K-Nearest Neighbors
 0:10:06
0:10:06
#48 K- Nearest Neighbour Algorithm ( KNN ) - With Example |ML|
 0:09:05
0:09:05
k nearest neighbor (kNN): how it works
 0:30:49
0:30:49
O KNN (K-Nearest Neighbors) - Algoritmos de Aprendizado de Máquinas
 0:06:30
0:06:30
1. Solved Numerical Example of KNN Classifier to classify New Instance IRIS Example by Mahesh Huddar
 0:15:38
0:15:38
K nearest neighbors (KNN) - explained | validation
 0:10:13
0:10:13
Lec-7: kNN Classification with Real Life Example | Movie Imdb Example | Supervised Learning
 0:17:42
0:17:42
7.5.1. K-Nearest Neighbors (KNN) - intuition
 0:15:30
0:15:30
ML 21 : K-Nearest Neighbor (KNN) Algorithm Working with Solved Examples
 0:03:48
0:03:48
KNN Algorithm in Machine Learning | K Nearest Neighbor | KNN Algorithm Example |Tutorialspoint
 0:09:24
0:09:24
How to implement KNN from scratch with Python
 0:00:46
0:00:46
K nearest neighbor
 0:07:13
0:07:13
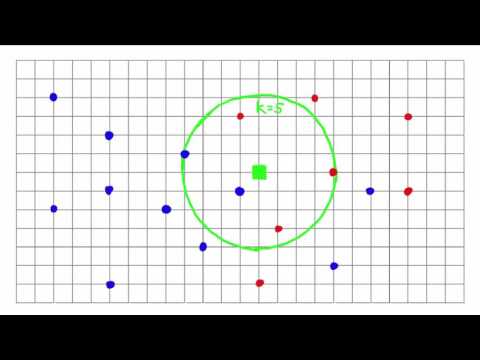
K-Nearest Neighbor
 0:06:15
0:06:15
k-nearest-neighbour KNN
 0:05:57
0:05:57
What Is The Difference Between KNN and K-means?
 0:06:11
0:06:11
Solved Example K Nearest Neighbors Algorithm Weighted KNN to classify New Instance by Mahesh Huddar
Комментарии