filmov
tv
Keynote - The Library, the Lab, and the Cabinet of Curiosities; integrating biodiversity data
Показать описание
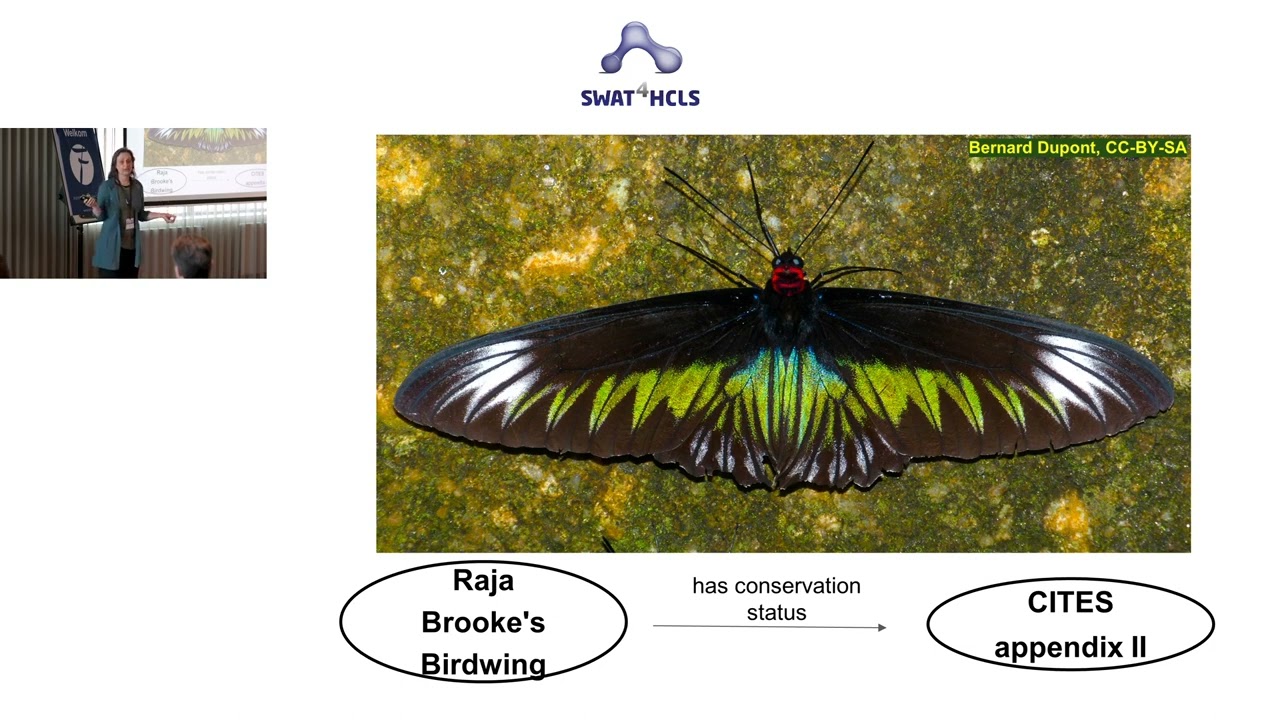
A brief tour of the particular challenges, goals, tactics, and [preferred] prevalent shortcuts and workarounds of semantic integration of biodiversity data. The original data capture may entail centuries-old paper in multiple languages, crowdsourced online photo-documentation, remote sensing, dried or preserved specimens, or environmental DNA sampled from various media. Methods for processing these data sources evolve rapidly, so the data deluge includes not only newly digitized historic knowledge and freshly recorded biotic occurrences and measurements, but also frequent revisions of existing batches of both. Data review and processing are performed by professional and volunteer humans and proprietary and open source code all over the world. The data include taxa, their relationships, the categories and properties with which they are described, the abiotic entities with which they are associated (eg: locality, habitat type) and the human and institutional agents responsible for each statement. Unique, stable, richly connected identifiers are our best hope of providing discoverability for this knowledge. It is an elusive goal, in the service of which semantic tools have been built, borrowed, stitched together, and stretched.
 0:57:56
0:57:56
 0:59:25
0:59:25
 1:05:36
1:05:36
 0:35:31
0:35:31
 1:11:59
1:11:59
 0:50:30
0:50:30
 0:02:11
0:02:11
 0:43:40
0:43:40
 0:05:22
0:05:22
 0:54:42
0:54:42
 1:02:06
1:02:06
 1:02:29
1:02:29
 0:59:39
0:59:39
 0:46:07
0:46:07
 1:07:34
1:07:34
 1:10:28
1:10:28
 0:58:47
0:58:47
 1:12:53
1:12:53
 0:30:14
0:30:14
 0:56:03
0:56:03
 1:39:29
1:39:29
 0:51:40
0:51:40
 1:02:11
1:02:11
 0:52:08
0:52:08