filmov
tv
XLDB2012
0:06:20
XLDB2012: Official Welcome
0:06:04
XLDB2012: Introducing the Big Data Benchmark Community
0:18:28
XLDB2012: Conference Introduction & Logistics
0:05:30
XLDB2012: Multi-temperature Data Management for XLDB Deployment
0:04:05
XLDB2012: NCBI Genotype Archive
0:05:41
XLDB2012: G-CODE Enables Actionable Clinical Knowledge from BIG DATA
0:05:10
XLDB2012: Real-time Analytics Streaming System at Zynga
0:34:33
XLDB2012: What can be done to make Hive a better database system?
0:05:29
XLDB2012: MongoDB and Big Data at CERN
0:05:19
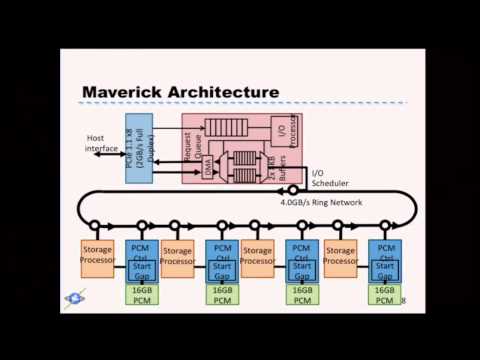
XLDB2012: Maverick: A Fast, Energy Efficient Next-Generation NVM-based SSD Architecture for Bio Apps
0:21:21
XLDB2012: Principles and Patterns in the Extreme Data & Analytics Ecosystem
0:47:59
XLDB2012: Big Data is (at least) Three Different Problems
0:08:51
XLDB2012: Closing Remarks
0:05:28
XLDB2012: Astronomical Data Processing Using SciQL, an SQL Based Query Language for Array Data
0:05:27
XLDB2012: How We Add Over One Billion Data Points Per Day in OpenTSDB
0:11:29
XLDB2012: Tradeoffs between Massively Parallel Analytical Systems
0:05:07
XLDB2012: Agrios: A Hybrid Approach to Scalable Data Analysis Systems
0:04:33
XLDB2012: Cataloging Scientific Data with araXne
0:05:15
XLDB2012: Parallel Data Storage, Analysis, and Visualization of a Trillion Particles
0:35:29
XLDB2012: Streaming and Compression Approaches for Terascale Biological Sequence Data Analysis
0:30:52
XLDB2012: Memory's Role in Improving the Efficiency of Extremely Large Databases
0:07:46
XLDB2012: Biology Bytes Back - Session Introductions
0:05:15
XLDB2012: Big-Data Analytics Usability
0:29:00
XLDB2012: Petascale Naturalistic Driving Study
Вперёд
join shbcf.ru
 0:06:20
0:06:20
 0:06:04
0:06:04
 0:18:28
0:18:28
 0:05:30
0:05:30
 0:04:05
0:04:05
 0:05:41
0:05:41
 0:05:10
0:05:10
 0:34:33
0:34:33
 0:05:29
0:05:29
 0:05:19
0:05:19
 0:21:21
0:21:21
 0:47:59
0:47:59
 0:08:51
0:08:51
 0:05:28
0:05:28
 0:05:27
0:05:27
 0:11:29
0:11:29
 0:05:07
0:05:07
 0:04:33
0:04:33
 0:05:15
0:05:15
 0:35:29
0:35:29
 0:30:52
0:30:52
 0:07:46
0:07:46
 0:05:15
0:05:15
 0:29:00
0:29:00